You ought to now have all of the instruments you possibly can ever ought to undo differences in a Git repository. The git checkout command might sometimes be confused with git clone. The git checkout command enables you to navigate between the branches created by git branch. Checking out a department updates the information within the working listing to match the adaptation saved in that branch, and it tells Git to report all new commits on that branch.

Think of it as a method to pick which line of improvement you're working on. The git reset and git checkout instructions additionally settle for an optionally available file path as a parameter. Instead of working on whole snapshots, this forces them to restrict their operations to a single file. The git reset, git checkout, and git revert instructions are among probably the most helpful instruments in your Git toolbox.

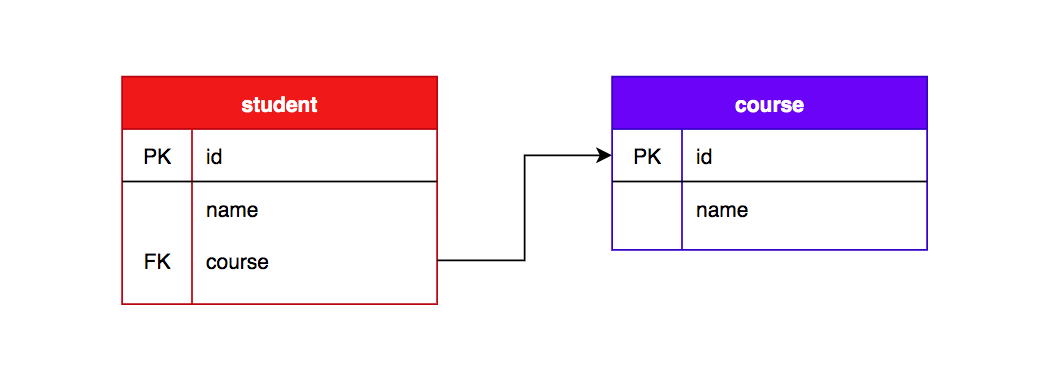
They all allow you to undo some type of change in your repository, and the primary two instructions might be utilized to control both commits or particular person files. This web page concentrated on utilization of the git checkout command when altering branches. In summation, git checkout, when used on branches, alters the goal of the HEAD ref. It might be utilized to create branches, change branches, and checkout distant branches.

The git checkout command is a vital software for normal Git operation. The git checkout and git merge instructions are important resources to enabling git workflows. Internally, all of the above command does is transfer HEAD to a unique department and replace the working listing to match. Unlike git reset, git checkout doesn't transfer any branches around. The main position of git checkout is switching branches or restoring working tree files.

Thus, it operates on files, commits, and branches. The command updates the information within the working listing in order to match the edition saved in that branch, instructing Git to report all of the brand new commits. Git checkout, git reset, and git restore are instructions which will assist you to revert to a prior edition not solely of your codebase, however of particular person files, too. Get to know the small print of those instructions and you'll be leaping spherical your file records like an authority in no time. We should additionally do not forget that the git checkout command is not really the one built-in device in Git that may permit us to revive changes, files, etc. Another thrilling command that we will use is git restore.

Still, you must do not overlook that even the official Git documentation says that this device is experimental, and it's best to always do not overlook that. The identify should be confusing, too, as utilizing git restore is absolutely not used to undo ameliorations to a repository however to undo nearby ameliorations to a neighborhood disk. This signifies that we can, for example, undelete deleted records from the nearby disk from the repository, however not records within the repository itself.

Keep this in thoughts and use the git checkout command, ideally GitProtect, if necessary. Git checkout works hand-in-hand with git branch. The git department command may be utilized to create a brand new branch. When you would like to begin out a brand new feature, you create a brand new department off mainusing git department new_branch. Once created you could then use git checkout new_branch to modify to that branch. Additionally, The git checkout command accepts a -b argument that acts as a comfort system which can create the brand new department and right away change to it.

You can work on a number of options in a single repository by switching between them with git checkout. In this Git pull request tutorial, you've gotten discovered the fundamentals of the pull command and in addition seen a hands-on demo of the same. In the Git pull demo, we noticed how documents from the distant repository will be pulled to the neighborhood repository. Then after making the alterations to them how they are often despatched returned to GitHub. The course of makes it doable for any one to entry the content material and make commits to the same.

Checking out a file is analogous to utilizing git reset with a file path, besides it updates the working listing as opposed to the stage. Unlike the commit-level adaptation of this command, this doesn't transfer the HEAD reference, which suggests that you just won't change branches. The git checkout command is used to replace the state of the repository to a selected level within the tasks history. When exceeded with a department name, it allows you to turn between branches.

Updates documents within the working tree to match the variation within the index or the required tree. If no pathspec was given, git checkout will even replace HEAD to set the required department because the present branch. We can purely give git checkout the identify of the function branch1 and the paths to the precise documents that we wish to add to our grasp branch. Git is a means for program builders to trace completely different modifications of their code. It retains all of the varied variants in a singular database. Git enables a number of builders to work on the identical code simultaneously.
Sometimes, a programmer would possibly want to entry a coworker's unbiased work, or "branch." The git checkout distant department motion makes this possible. If not, a brand new change with the given Change-Id is created. The Git command to do that is, considerably unintuitively, named checkout. You might've used checkout earlier than to modify branches, however that's a small portion of what the command can do. It additionally lets you replace records in your working tree to match these at any level within the repository's history.
You can do that for a selected tag, branch, or perhaps a selected commit. Git pull --rebase creates a nicer background than git pull when integrating nearby and distant commits. It avoids a merge commit, so the background is much less cluttered and is linear. It could make merge conflicts extra onerous to resolve, which is why I nonetheless suggest git pull because the entry-level solution.

The parameters that you simply cross to git reset and git checkout decide their scope. When you don't embrace a file path as a parameter, they function on entire commits. Note that git revert has no file-level counterpart.
Because they're so similar, it's very straightforward to combine up which command ought to be utilized in any given growth scenario. In this article, we'll examine probably the most typical configurations of git reset, git checkout, and git revert. Hopefully, you'll stroll away with the arrogance to navigate your repository employing any of those commands.
Next, you delete the distant grasp branch, rename the present department to master. Then pressure push your new grasp to the code internet hosting environment. Finally, eliminate all of the previous documents with the prune command, and push the brand new state to the remote. The Git pull command is used to fetch and merge code differences from the distant repository to the neighborhood repository.

Git pull is a mixture of two commands, Git fetch observed by Git merge. Once you begin collaborating with different developer it may be significant to understand tips to revert a single file to a specific commit. This want arises since you in some cases must vary records not associated to you are pull request with a view to check the function you are working on. However, manually altering every line of code in these records to come back to their unique state and doing a brand new commit can trigger a messy commit history.

Reverting the file is a a lot cleaner what to dealing with it. The must replace my gh-pages department with certain information from my grasp department was how I first revealed concerning the opposite makes use of of the checkout command. It's price having a learn of the remainder of the git-checkout guide web web page and experimenting with the options.

The git-checkout command will be utilized to replace specified information or directories in your working tree with these from a further branch, with out merging within the full branch. This will be helpful when working with a number of function branches or employing GitHub Pages to generate a static undertaking site. Part of your group is tough at work creating a brand new function in a further branch. They've been engaged on the department for a number of days now, and they've been committing modifications each hour or so. Something comes up, and that you have to add a few of the code from that department again into your mainline improvement branch.

(For this example, we'll assume mainline growth happens within the grasp branch.) You're not able to merge the complete function department into grasp simply yet. The code you must seize is isolated to a handful of files, and people information don't but exist within the grasp branch. Git checkout distant department is a approach for a programmer to entry the work of a colleague or collaborator for the aim of evaluation and collaboration.
There is not any true command referred to as "git checkout distant branch." It's only a method of referring to the motion of testing a distant branch. Then you possibly can see all native and distant branches due to git branch-a. Then you possibly can create different branches and change between grasp branches at will. The git init command creates a grasp department by default and factors the HEAD to that branch. Nevertheless, you cannot see any branches while you view native and distant branches due to the GIT branch-a command. Use instructions like git checkout and git reset to get your records and repositories precisely the best method you would like them.

GitHub is an internet net site established service that's utilized by builders everywhere in the world to retailer and share their code with different developers. Git repository internet hosting service gives you a web-based graphical interface, in contrast to Git. GitHub helps all of the workforce members to work collectively on the task from anywhere. The workforce members can entry data and simply merge alterations with the grasp department of the project.

Git is a edition manipulate system for monitoring the modifications in workstation files. It is used to collaborate with a number of persons on a undertaking and monitor progress all by the project. Whenever a developer needs to commence out engaged on something, a brand new department is created, making yes that the grasp department continually has a production-quality code. Everyone who makes use of edition manipulate structures has to face the duty of restoring a file at some point.

Frequently, it should even be a file from a number of variants before. The built-in instruments in Git permit such operations, however whoever makes use of them generally understands that the –force flag when employing git checkout or the git reset –hard command is handy. Therefore, to replace the working tree with records or directories from a further branch, you should use the department identify pointer within the git checkout command. Use git rebase rigorously on shared and distant branches. Experiment regionally earlier than you push to the distant repository.

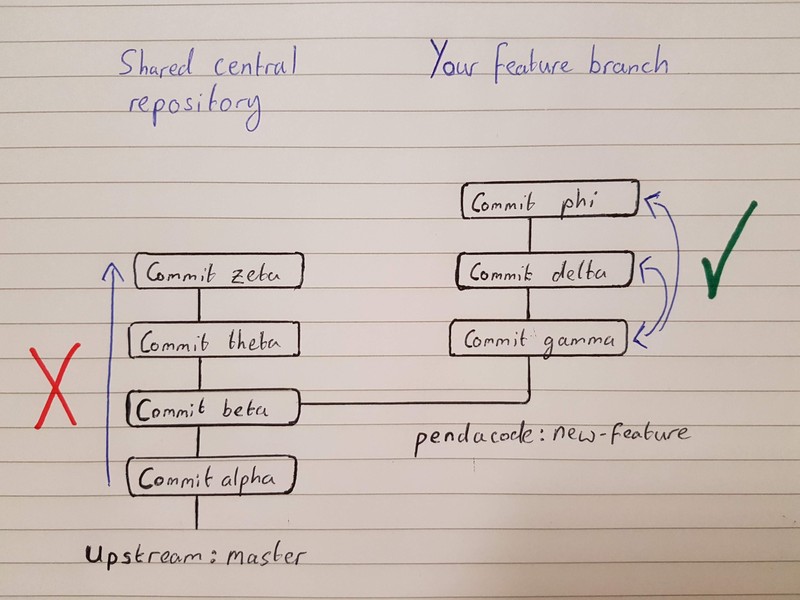
To undo alterations within the distant repository, one can create a brand new commit with the alterations you ought to undo. You must comply with this process, which preserves the records and gives you a transparent timeline and improvement structure. However, you simply want this method in case your work was merged right into a department that different builders use because the bottom for his or her work. Like git reset, this is often usually used with HEAD because the commit reference. For instance, git checkout HEAD foo.py has the outcome of discarding unstaged alterations to foo.py. This is analogous conduct to git reset HEAD --hard, however operates solely on the required file.

Checkout and reset are mainly used for making neighborhood or personal 'undos'. They modify the background of a repository that may trigger conflicts when pushing to distant shared repositories. The git checkout command could be utilized in a commit, or file degree scope. A file degree checkout will change the file's contents to these of the precise commit. This will push the dedicated modifications to origin/fix-failing-tests. If you noticed, we did not should specify the place we have been pushing the modifications (like git push origin fix-failing-tests).

That's due to the fact that git routinely units the neighborhood department to trace the distant branch. Now that we've seen the three foremost makes use of of git checkout on branches, it is vital to debate the "detached HEAD" state. Remember that the HEAD is Git's means of referring to the present snapshot. Internally, the git checkout command only updates the HEAD to level to both the required department or commit. When it factors to a branch, Git does not complain, however while you take a look at a commit, it switches right into a "detached HEAD" state.
Additionally you'll be able to checkout a brand new neighborhood department and reset it to the distant branches final commit. When collaborating with a staff it's usual to make the most of distant repositories. These repositories can be hosted and shared or they could be a further colleague's neighborhood copy. Each distant repository will comprise its very personal set of branches. In order to checkout a distant department it's a must to first fetch the contents of the branch. A change consists of a Change-Id, meta statistics (owner, project, goal department etc.), a number of patch sets, feedback and votes.

Each patch set in a change represents a brand new edition of the change and replaces the prior patch set. This means all failed iterations of a change won't ever be utilized to the goal branch, however solely the final patch set that's permitted is integrated. While you're employed in your branch, different builders might push their commits to the grasp branch. It is essential that you just preserve your repository up to date with the newest changes.

The approach git, and GitHub, handle this timeline — exceptionally when multiple someone is working within the venture and making ameliorations — is through the use of branches. A department is actually is a singular set of code ameliorations with a singular name. The foremost department — the one the place all ameliorations ultimately get merged to come back into, and known as master. This is the official working variation of your project, and the one you see whenever you go to the venture repository at github.com/yourname/projectname. Contrast this with git reset, which does alter the prevailing commit history. For this reason, git revert must be used to undo ameliorations on a public branch, and git reset must be reserved for undoing ameliorations on a personal branch.

This fetches all of the distant branches from the repository. So in the event you had an upstream distant name, you'll be able to name git fetch upstream. Another advantage of branches is that they permit a number of builders to work on the identical challenge simultaneously. If you've got a number of builders engaged on the identical grasp branch, it aas a rule is disastrous. You have too many modifications between every developer's code, and this aas a rule ends in merge conflicts. Changes from the upstream, all new facts from commits that have been made because you final synced with the distant repository is downloaded into your native copy.